le réseau du métro parisien#
Licence CC BY-NC-ND, Thierry Parmentelat
commencez par télécharger le zip

intérêts de ce TP
découvrir deux algos hyper classiques de parcours de graphes (simples, élégants, et très utiles!)
utiliser des données hybrides pandas et Python
utiliser les properties
mettre en oeuvre une librairie de rendu géographique (folium)
from pathlib import Path
import numpy as np
import pandas as pd
introduction#
les données#
on vous a préparé deux jeux de données qui décrivent le métro parisien
# a few constants
data = Path("data")
# load the data
stations = pd.read_csv(data / "stations.txt", index_col="station_id")
hops = pd.read_csv(data / "hops.txt")
stations.head()
| latitude | longitude | |
|---|---|---|
| station_id | ||
| 2122 | 48.866856 | 2.290038 |
| 2177 | 48.829863 | 2.350623 |
| 2399 | 48.845323 | 2.401786 |
| 3901291 | 48.906667 | 2.365230 |
| 2065 | 48.841432 | 2.400869 |
hops.head()
| from_station_id | to_station_id | line | |
|---|---|---|---|
| 0 | 2122 | 2517 | 6 |
| 1 | 2122 | 1909 | 6 |
| 2 | 2177 | 2217 | 6 |
| 3 | 2399 | 2065 | 6 |
| 4 | 3901291 | 1743 | 12 |
SOURCE : à l’origine la source de ces données est la RATP et plus précisément ceci, prétraité par nos soins
DISCLAIMER comme vous le verrez ces données ne sont pas parfaites, mais dans l’ensemble c’est un niveau de qualité suffisant pour notre propos d’aujourd’hui.
ce qu’on veut en faire#
dessiner le réseau sur une carte
s’en servir de support pour visualiser deux algorithmes de parcours de graphe
DFS : depth-first-search
BFS : breadth-first-search
les algorithmes de parcours#
Il y a deux algorithmes standard pour parcourir un graphe à partir de l’un de ses sommets :
DFS (depth-first-scan)
BFS (breadth-first scan)
intuitivement, en partant de cet échantillon (ici un simple DAG - Directed Acyclic Graph) :

DFS donnerait l’énumération suivante (les sauts de ligne ne sont pas significatifs) :
v v1 v11 v111 v112
v12 v113
v2 v21 v211 v212
v22 v213
alors que BFS verrait au contraire :
v v1 v2
v11 v12 v21 v22
v111 v121 v122 v211 v212 v222
pour simplifier au maximum les deux algorithmes de parcours que l’on veut implémenter, on peut les décrire informellement de la façon suivante :
en entrée on nous passe le sommet qui sert de point de départ
starton initialise un ensemble vide de sommets
scanned, qui contiendra tous les sommets qu’on a déjà parcouruson initialise une file d’attente
waiting_area, dans laquelle on metstartle parcours consiste alors à faire, tant que
waiting_arean’est pas vide :prendre (et enlever) un élément
nextdewaiting_areal’afficher (ou en faire ce que le parcours doit en faire)
ajouter
nextdansscannedpour matérialiser le fait qu’on y est déjà passépour tous les voisins de
waiting_areaqui ne sont pas encore dansscanned:
les ajouter danswaiting_area
ce qui est assez remarquable, c’est que les deux ordres de parcours (DFS et BFS) peuvent être toutes les deux réalisés avec ce même algorithme, la seule chose qui change entre les deux étant l’ordre dans lequel waiting_area “rend” les choses qu’on y insère; ainsi
si
waiting_areaest une FILO (first-in-last-out), l’algorithme ci-dessus fait un parcours DFSet inversement si
waiting_areaest une FIFO (first-in-first-out), alors on parcourt le graphe en BFS
c’est ce que nous visualiserons à la fin de ce TP
structures de données - intro#
on va représenter le graphe avec plusieurs classes d’objet :
Station: contient les détails de l’arrêt ; ici on n’a gardé, parmi tous les détails exposés par la RATP, que les coordonnées latitude et longitude, mais dans un exemple plus réaliste on pourrait avoir ici plein de détails…Node: modélise un noeud (sommet) dans le graphe, et ses noeuds voisins ;Graph: contient l’ensemble des noeuds du réseau.
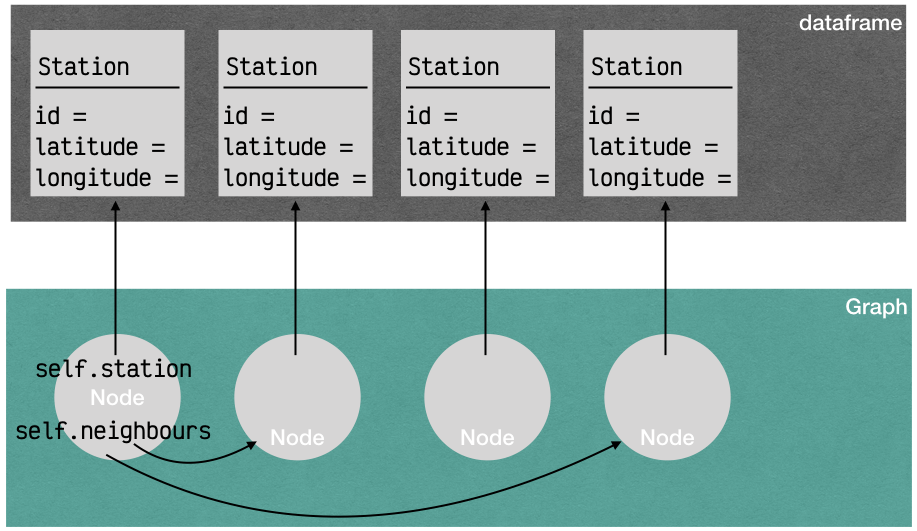
spécifications#
specs (1) : construction du graphe#
voici pour commencer le code qu’on aimerait pouvoir écrire
# on rappelle que stations et hops sont des dataframes
# on peut itérer sur les lignes d'une dataframe avec iterrows()
def build_graph(stations: pd.DataFrame, hops: pd.DataFrame):
graph = Graph()
# créer un node par station
for index, station in stations.iterrows():
node = graph.add_node(station)
# créer une arête par hop, annotée par le numéro de ligne
for index, hop in hops.iterrows():
graph.add_edge(hop['from_station_id'], hop['to_station_id'], hop['line'])
return graph
ainsi une fois qu’on aura implémenté la classe Graph (et la classe Node sous-jacente) on pourra construire notre graphe en écrivant
metro = build_graph(stations, hops)
specs (2) : dessin de la carte#
pour ce qui est d’afficher le réseau sur une carte, le code qu’on va vouloir écrire ressemble à ceci (on reparlera plus en détail de la librairie folium en temps voulu) :
def build_map(metro: Graph, show_labels=True):
map = folium.Map(...)
for node in metro.iter_nodes():
# si le noeud a un label
if show_labels and node.label:
# l'afficher à la position du noeud
# donc on a besoin d'accéder à
node.latitude, node.longitude, node.label
# quand on itère sur les arêtes on retourne
# un triplet avec le numéro de ligne
# qu'on utilisera ici pour trouver la couleur attachée à chaque ligne
for node, neighbour, line in metro.iter_edges():
# pour tracer un trait entre les deux
# on a besoin d'accéder à
(node.latitude, node.longitude),
(neighbour.latitude, neighbour.longitude)
return map
specs (3) : parcours#
en ce qui concerne les algorithmes de parcours, compte tenu de ce qu’on a vu plus haut, le code qu’on va vouloir écrire aura besoin aussi d’itérer sur les voisins d’un noeud, et ressemblera schématiquement à ceci :
def scan(start_node, storage):
storage.store(start_node)
...
while storage:
current_node = storage.retrieve()
...
for neighbour, line in current_node.iter_neighbours():
storage.store(neighbour)
specs : résumé#
pour résumer les besoins sur les classes Graph et Node, on va vouloir être en mesure d’écrire ce genre de choses:
# création
node = graph.add_node(station)
graph.add_edge(
from_station_id, to_station_id, line)
# parcours des noeuds
for node in graph.iter_nodes():
# accès à partir d'un noeud
node.station, node.label
node.latitude, node.longitude
# parcours des arêtes
for node, neighbour, line in graph.iter_edges():
...
for neighbour, line in node.iter_edges():
...
et on peut ajouter quelques fonctions de confort
# le nombre de noeuds
len(graph)
# le nombre d'arêtes dans un graphe
graph.nb_edges()
# trouver un noeud dans le graphe
graph.find_node_from_station_id(station_id)
# le nombre d'arêtes
node.nb_edges()
implémentation#
le type Station#
pour le type Station on n’a rien à écrire, c’est l’intérêt d’avoir séparé la couche ‘données’ (dataframe) de la couche ‘connectivité’ (Graph), un objet de type Station est en fait une instance de pandas.Series
et rappelez-vous, pour accéder à une dataframe on peut utiliser:
df.loc[]pour les accès par index (notre cas ici)df.iloc[]pour les accès par indice (pas utile ici)
du coup, voici comment utiliser les objets de type Station
# le type Station correspond à une ligne
# dans la dataframe chargée à partir de stations.txt
# ce serait assez redondant d'avoir à se redéfinir un type pour cela
# et grâce à la dataframe - que l'on a indexée par station_id
# on peut trouver la station correspondant à un station_id
# par accès direct (comme dans un dictionnaire)
# si je cherche par exemple la station dont l'id vaut 2152
station_sample = stations.loc[2152]
station_sample
latitude 48.887086
longitude 2.349370
Name: 2152, dtype: float64
# pour accéder aux positions géographiques c'est simple
station_sample.latitude
np.float64(48.88708628305045)
# par contre pour accéder au station_id, qui sert d'index,
# c'est différent
try:
station_sample.station_id
except Exception as exc:
print(f"OOPS - {type(exc)} : {exc}")
OOPS - <class 'AttributeError'> : 'Series' object has no attribute 'station_id'
# il faut utiliser l'attribut name (ça n'est pas très logique d'ailleurs !)
station_sample.name
np.int64(2152)
station_sample.name
np.int64(2152)
# quel est le type de cet objet
type(station_sample)
pandas.core.series.Series
# définissons un type pour les type hints
Station = pd.Series
le type Node#
pour modéliser les relations entre stations, on enrobe le type Station avec un objet Node qui possède une référence vers une station, et aussi vers les noeuds voisins
la première idée consisterait à garder dans un attribut self.neighbours un set d’objets Node (c’est d’ailleurs ce qu’on a représenté sur le diagramme simplifié ci-dessus)
mais il se trouve que dans hops.txt on nous donne aussi le numéro de la ligne de métro qui connecte deux stations, on va donc vouloir attacher à chaque lien ce numéro de ligne, et du coup un ensemble n’est sans doute pas ce qu’il y a de mieux…
# à vous de compléter le code
class Node:
"""
a node has a reference to a unique Station object
and also logically a set of neighbours,
each tagged with a line among the 14 metro lines
finally it has an optional 'label' attribute that we will use when
drawing the graph on a map
"""
def __init__(self, station: "Station"):
# votre code ici ..
pass
def add_edge(self, neighbour: "Node", line):
# votre code ici ..
pass
def nb_edges(self):
# votre code ici ..
pass
def iter_neighbours(self):
"iterates (neighbour, line) over neighbours"
# votre code ici ..
pass
# we will also need these 2 attributes (so, refer to: properties)
# node.latitude
# node.longitude
# version étudiant : à vous de compléter le code
# NOTE : vous remarquerez qu'on a choisi de créer les arêtes
# à partir de `station_id`s
# il faut donc pouvoir retrouver un noeud à partir de cette information
class Graph:
"""
the toplevel object that models the complete graph
as essentially a set of nodes (thus of stations)
"""
def __init__(self):
# votre code ici ..
pass
def add_node(self, station):
"""
insert a station in graph; duplicates are simply ignored
"""
# votre code ici ..
pass
def find_node_from_station_id(self, station_id):
"""
spot a node from a specific station id
"""
# votre code ici ..
pass
def add_edge(self, from_station_id, to_station_id, line):
"""
insert an edge - both ends must exist already
"""
# votre code ici ..
pass
def iter_nodes(self):
"""
an iterator on nodes
"""
# votre code ici ..
pass
def iter_edges(self):
"""
iterates over triples (node_from, node_to, line)
"""
# votre code ici ..
pass
# ... ajoutez ce dont vous avez besoin
construction du graphe#
maintenant on devrait pouvoir construire le graphe
metro = build_graph(stations, hops)
print(f"notre graphe a {len(metro)} stations et {metro.nb_edges()} liens")
---------------------------------------------------------------------------
TypeError Traceback (most recent call last)
Cell In[17], line 3
1 metro = build_graph(stations, hops)
----> 3 print(f"notre graphe a {len(metro)} stations et {metro.nb_edges()} liens")
TypeError: object of type 'Graph' has no len()
# exercice: calculer le nombre de lignes
nb_lines = ...
print(nb_lines)
dessiner le graphe sur une carte#
on va utiliser la librairie folium pour afficher les cartes
pas de code à écrire de votre part dans cette partie, mais vous pouvez prendre le temps de voir comment c’est fait
import folium
STATION_RADIUS = 100
MARKER_DIAMETER = 20
LINE_WIDTH = 7.5
STATION_COLOR = '#d22'
les couleurs des lignes#
from nuancier import nuancier
nuancier
afficher les labels#
pour mettre en évidence une station (un peu fastidieux en folium)
from labelicon import label_icon
Chatelet au centre de la carte#
chatelet_station_id = 2221
chatelet_station = stations.loc[chatelet_station_id]
map_center = [chatelet_station['latitude'], chatelet_station['longitude']]
ma première carte en folium#
autre_station = stations.loc[2122]
autre_position = [autre_station['latitude'], autre_station['longitude']]
une_couleur = nuancier["7"]
On n’aura besoin que des classes suivantes
folium.mapfolium.map.Markerpour attacher un label à chaque stationfolium.Circlefolium.PolyLinepour tracer un trait
map = folium.Map(location=map_center, zoom_start=13)
folium.map.Marker(map_center, icon=label_icon('0')).add_to(map)
folium.Circle(map_center, STATION_RADIUS,
fill=True, fill_color=une_couleur).add_to(map)
folium.map.Marker(autre_position, icon=label_icon('100')).add_to(map)
folium.Circle(autre_position, STATION_RADIUS,
fill=True, fill_color=une_couleur).add_to(map)
folium.PolyLine([map_center, autre_position],
weight=LINE_WIDTH, color=une_couleur).add_to(map)
map
contruire une folium.Map à partir du graphe#
Nous voulons visualiser les stations, et les lignes. En option (si show_labels=True), on affichera aussi l’attribut label des objets Node lorsqu’il est défini.
def build_map(metro, show_labels=True):
map = folium.Map(location=map_center, zoom_start=13)
for node in metro.iter_nodes():
if show_labels and node.label:
folium.map.Marker(
[node.latitude-0.0001, node.longitude-0.0001],
icon=label_icon(node.label)
).add_to(map)
folium.Circle(
[node.latitude, node.longitude],
STATION_RADIUS,
fill=True,
fill_color=STATION_COLOR,
).add_to(map)
for node, neighbour, line in metro.iter_edges():
line_color = nuancier[line]
locations = [(node.latitude, node.longitude),
(neighbour.latitude, neighbour.longitude)]
folium.PolyLine(locations=locations,
weight=LINE_WIDTH, color=line_color).add_to(map)
return map
à ce stade si votre code pour Node et Graph est correct vous pouvez voir ici la carte du réseau avec la station Chatelet numérotée 0
# on met au moins un label pour voir l'effet
metro.find_node_from_station_id(chatelet_station_id).label = '0'
build_map(metro)
parcours : implémentation et illustration#
rappel des objectifs#
nous voulons écrire un generateur qui implémente les deux stratégies de parcours, à partir d’un sommet du graphe
bien entendu, seuls les sommets accessibles seront parcourus, ce qui dans notre cas n’a pas d’importance puisque le graphe du métro est connexe
nous avons vu qu’on pouvait unifier les deux parcours, en utilisant une file d’attente FIFO ou FILO selon le parcours que l’on veut faire
nous avons simplement besoin dans les deux cas d’un objet Storage qui implémente store() et retrieve() avec la bonne politique; aussi de manière accessoire on a besoin de pouvoir tester si une file est vide ou non, c’est à dire de pouvoir écrire while storage: ...
FIFO / FILO#
à vous d’implémenter les deux classes suivantes
from collections import deque
class Fifo:
def __init__(self):
pass
def store(self, item):
pass
def retrieve(self):
pass
# pour 'while storage:'
def __len__(self):
pass
from collections import deque
class Filo:
def __init__(self):
pass
def store(self, item):
pass
def retrieve(self):
pass
# ditto
def __len__(self):
pass
# pour vérifier
fifo = Fifo()
for i in range(1, 4):
fifo.store(i)
while fifo:
print(f"retrieve → {fifo.retrieve()}")
# pour vérifier
filo = Filo()
for i in range(1, 4):
filo.store(i)
while filo:
print(f"retrieve → {filo.retrieve()}")
parcours générique#
vous avez à présent toutes les informations pour écrire vous-même la fonction suivante, qui va nous servir ensuite à implémenter les deux parcours (voyez les cellules suivantes)
# avec nos spécifications, on peut écrire le parcours
# en utilisant principalement
# for neighbour, line in node.iter_neighbours():
def scan(start_node, storage):
"""
scan all vertices reachable from start vertex
in an order that is DF or BF depending on the
storage policy (fifo or filo)
storage should have store() and retrieve() methods
and be testable for emptiness (if storage: ...)
also it should be empty when entering the scan
"""
pass # your code here
les deux parcours spécifiques#
# depth first search becomes just this:
def DFS(metro, station):
node = metro.find_node_from_station_id(station.name)
storage = Filo()
yield from scan(node, storage)
# and likewise for breadth first search
def BFS(metro, station):
node = metro.find_node_from_station_id(station.name)
storage = Fifo()
yield from scan(node, storage)
illustration#
pour illustrer les deux parcours, on va simplement utiliser l’attribut label des noeuds, et y ranger l’ordre dans lequel se fait le parcours
si tout se passe bien vous allez voir le réseau du métro parisien, avec les stations numérotées selon ces deux algorithmes
depth-first scan#
# labelling all stations according to a DFS scan
for index, node in enumerate(DFS(metro, chatelet_station)):
node.label = str(index)
print(f"index={index}")
build_map(metro)
breadth-first scan#
# same with a BFS
for index, node in enumerate(BFS(metro, chatelet_station)):
node.label = str(index)
print(f"index={index}")
build_map(metro)
un dernier mot : instances hashables#
vous avez peut-être utilisé un ensemble pour mémoriser dans la fonction scan() les sommets parcourus; en tous cas c’est assez logique d’y penser
je signale à ce sujet que par défaut, une instance de classe peut être insérée dans un ensemble; ce qui peut sembler contredire un peu ce qu’on a vu au sujet des types prédéfinis, à savoir qu’un ensemble ne peut contenir que des objets immutables
en fait par défaut, lorsqu’on insère une instance dans un ensemble, ce qui sert de clé pour le hachage c’est le résultat de id(), c’est-à-dire en gros l’adresse de l’instance
dans le cas qui nous intéresse ici, on a créé des instances de Node, on peut effectivement les mettre dans un ensemble sans trop de précaution, il y a des chances pour que ça fonctionne tout seul (typiquement si on crée une seule instance de Node par station de métro)
mais bon, si on veut être propre (don’t program by coincidence…), il est intéressant de redéfinir 2 dunder (sur la classe Node donc) pour que les recherches dans l’ensemble soient pertinentes; il s’agit des dunder __hash__ et __eq__ que je vous invite à implémenter si vous ne l’avez pas fait.
comment on se propose de le faire#
construire une structure de données pour
ranger le graphe,
pouvoir le parcourir rapidement/efficacement
afficher la carte avec la librairie
foliumparcours :
implémenter les 2 parcours de graphe
numéroter les stations (en partant de Chatelet) selon les deux parcours
afficher les résultats