fetch the Internet#
JSON#
commençons par une donnée en JSON; par exemple ceci samayo/country-json
pour trouver le bon lien, je clique sur ‘Raw’ et je copie ici
URL1 = "https://raw.githubusercontent.com/samayo/country-json/master/src/country-by-population.json"
Il s’agit pour nous d’écrire un code qui va chercher cette donnée et les traduit en une structure Python
(à base de list et dict) -
la structure en question est déjà présente dans le JSON.
Indices sur la librairie requests#
ce module ne fait pas partie de la librairie standard, il faut l’installer avec .. wait for it
pip install requests
(il y a des fonctions de ce genre dans la librairie standard, mais c’est celle-ci qui est le plus souvent utilisée)
poster la requête#
import json
import requests
# il faut être un peu patient, surtout si votre réseau est un peu lent
response = requests.get(URL1)
les attributs de l’objet response#
# dans ce genre de cas dir() est utile
# sauf que c'est un peu trop bavard
# dir(response)
# du coup ça vaut le coup de filter un peu
[symbol for symbol in dir(response) if not symbol.startswith('_')]
['apparent_encoding',
'close',
'connection',
'content',
'cookies',
'elapsed',
'encoding',
'headers',
'history',
'is_permanent_redirect',
'is_redirect',
'iter_content',
'iter_lines',
'json',
'links',
'next',
'ok',
'raise_for_status',
'raw',
'reason',
'request',
'status_code',
'text',
'url']
# si tout s'est bien passé ici on doit avoir 200
# (pour être précis: entre 200 et 299)
# c'est un des codes de retours de HTTP
# si c'est par exemple 404 ça signifie que cette URL n'existe plus
response.status_code
200
# si on était curieux on pourrait aussi faire
response.headers
{'Connection': 'keep-alive', 'Content-Length': '3197', 'Cache-Control': 'max-age=300', 'Content-Security-Policy': "default-src 'none'; style-src 'unsafe-inline'; sandbox", 'Content-Type': 'text/plain; charset=utf-8', 'ETag': 'W/"81c9e62269c8660e7bf10f234993c94c4ea4dc2b725e4bd5f2df78505cab71e7"', 'Strict-Transport-Security': 'max-age=31536000', 'X-Content-Type-Options': 'nosniff', 'X-Frame-Options': 'deny', 'X-XSS-Protection': '1; mode=block', 'X-GitHub-Request-Id': 'E123:6F396:F9438:138C6E:68CEABCC', 'Content-Encoding': 'gzip', 'Accept-Ranges': 'bytes', 'Date': 'Sat, 20 Sep 2025 13:27:40 GMT', 'Via': '1.1 varnish', 'X-Served-By': 'cache-cmh1290096-CMH', 'X-Cache': 'MISS', 'X-Cache-Hits': '0', 'X-Timer': 'S1758374861.719623,VS0,VE157', 'Vary': 'Authorization,Accept-Encoding', 'Access-Control-Allow-Origin': '*', 'Cross-Origin-Resource-Policy': 'cross-origin', 'X-Fastly-Request-ID': 'aae6fda7e19ec85c22eab31746a0687c208ab6a9', 'Expires': 'Sat, 20 Sep 2025 13:32:40 GMT', 'Source-Age': '0'}
# pour voir par exemple la taille de notre donnée
response.headers['Content-Length']
'3197'
# mais bon, bien sûr ce qu'on veut surtout c'est le contenu
# c'est une chaine, regardons les 100 premiers caractères
print(type(response.text))
print(response.text[:100], '...')
<class 'str'>
[
{
"country": "Afghanistan",
"population": 37172386
},
{
"count ...
indices sur la librairie json#
pour le coup, elle est dans la stdlib; les deux méthodes intéressantes sont
json.loads(json_string)qui décode une chaine JSON en un objet Python, etjson.dumps(object)qui encode un object Python en une chaine JSON
le code#
du coup le code que je dois écrire pour faire le job est simplement
def get_url_as_json(url):
"""
Fetch a URL and decode its result as JSON
"""
with requests.get(url) as response:
return json.loads(response.text)
python_friendly = get_url_as_json(URL1)
# on obtient quoi comme type ?
type(python_friendly)
list
python_friendly[:3]
[{'country': 'Afghanistan', 'population': 37172386},
{'country': 'Albania', 'population': 2866376},
{'country': 'Algeria', 'population': 42228429}]
python_friendly[-3:]
[{'country': 'Yemen', 'population': 28498687},
{'country': 'Zambia', 'population': 17351822},
{'country': 'Zimbabwe', 'population': 14439018}]
len(python_friendly)
244
option: transformer la structure#
# et ici par exemple je pourrais décider que c'est plus pratique
# sous la forme d'un dictionnaire name -> population
population = {d['country']: d['population'] for d in python_friendly}
# de sorte que je peux faire simplement
population['France']
66977107
CSV#
Vous trouverez à cette URL un accès aux données de population par pays datasets/population
Attention
ce ne sont pas les mêmes données exactement, celles-ci sont beaucoup plus détaillées…
# pareil, on clique sur 'Raw' pour obtenir le lien vers la donnée 'crue'
URL2 = "https://raw.githubusercontent.com/datasets/population/main/data/population.csv"
# il faut être un peu patient car c'est bcp + gros que tout à l'heure
response = requests.get(URL2)
response.headers['Content-Length']
'130037'
indices sur la librairie csv#
# il semble donc qu'on ait affaire à un csv classique
# qu'on peut décortiquer avec object csv.reader
# https://docs.python.org/3/library/csv.html
import csv
il se trouve que la librairie csv fournit un objet csv.reader qui prend un paramètre de type file
c’est-à-dire comme par exemple le résultat de open()
ça demande une petite gymnastique, car nous avons le texte en mémoire, et pas dans un fichier…
option 1 - pas beau !#
très inélégant, mais qui peut marcher à la rigueur:
j’ai une chaine, je l’écris dans un fichier, que je peux ensuite rouvrir en lecture pour le passer à csv.reader …
une option viable en dernier recours, mais on ne va pas le faire, car c’est très vilain, et il y a une astuce pour s’en sortir autrement:
option 2 - mieux#
exactement pour contourner ce genre de cas, il y a une classe io.StringIO qui, en partant d’une chaine en mémoire, se comporte comme un fichier ! et donc on va utiliser cela :
# pour utiliser csv.reader, il nous faut un objet de type fichier (file-like object)
# et c'est là que StringIO est super pratique
from io import StringIO
with (StringIO(response.text)) as file_like:
reader = csv.reader(file_like, delimiter=',')
# on regarde juste les 3 premiers enregistrements
for i, row in enumerate(reader, 1):
print(i, row)
if i >= 3:
break
1 ['Country Name', 'Country Code', 'Year', 'Value']
2 ['Aruba', 'ABW', '1960', '54922']
3 ['Aruba', 'ABW', '1961', '55578']
À ce stade, on voit comment on peut transformer nos données en listes Python; mais on va s’arrêter là, parce qu’en pratique ça c’est vraiment un exercice qu’on ferait en pandas…
un aperçu de pandas#
pandas est une librairie externe aussi, qu’il faut absolument connaitre un peu, dès qu’on manipule de la data
et pour commencer il y a une fonction read_csv qui va faire le job complet (acquisition et chargement) en un seul appel:
import pandas as pd
# en vrai on fait comme ça: être patient .. à nouveau
df = pd.read_csv(URL2)
# on regarde un peu ce qu'il y a dedans
df.head(3)
# on peut aussi regarder la fin avec df.tail(3)
| Country Name | Country Code | Year | Value | |
|---|---|---|---|---|
| 0 | Aruba | ABW | 1960 | 54922.0 |
| 1 | Aruba | ABW | 1961 | 55578.0 |
| 2 | Aruba | ABW | 1962 | 56320.0 |
# conversion en date
df['time'] = pd.to_datetime(df.Year, format="%Y")
df.head(3)
| Country Name | Country Code | Year | Value | time | |
|---|---|---|---|---|---|
| 0 | Aruba | ABW | 1960 | 54922.0 | 1960-01-01 |
| 1 | Aruba | ABW | 1961 | 55578.0 | 1961-01-01 |
| 2 | Aruba | ABW | 1962 | 56320.0 | 1962-01-01 |
# on nettoie / renomme
del df['Year']
df = df.rename(columns = {
'Country Name': 'country',
'Country Code': 'code',
'Value': 'population',
})
df.head(2)
| country | code | population | time | |
|---|---|---|---|---|
| 0 | Aruba | ABW | 54922.0 | 1960-01-01 |
| 1 | Aruba | ABW | 55578.0 | 1961-01-01 |
# on choisit un index un peu plus parlant
df = df.set_index('time')
df.head(2)
| country | code | population | |
|---|---|---|---|
| time | |||
| 1960-01-01 | Aruba | ABW | 54922.0 |
| 1961-01-01 | Aruba | ABW | 55578.0 |
# on se définit arbitrairement une période qui nous intéresse
begin = pd.to_datetime('1980', format='%Y')
end = pd.to_datetime('2010', format='%Y')
# on filtre ce qui nous intéresse
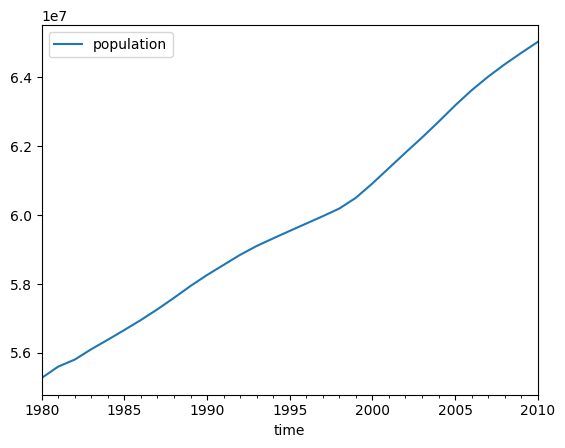
df_france = df[(df.country == 'France') & (df.index >= begin) & (df.index <= end)]
df_france.head
<bound method NDFrame.head of country code population
time
1980-01-01 France FRA 55274184.0
1981-01-01 France FRA 55603353.0
1982-01-01 France FRA 55806789.0
1983-01-01 France FRA 56108330.0
1984-01-01 France FRA 56383085.0
1985-01-01 France FRA 56665619.0
1986-01-01 France FRA 56956002.0
1987-01-01 France FRA 57266167.0
1988-01-01 France FRA 57598186.0
1989-01-01 France FRA 57943062.0
1990-01-01 France FRA 58261012.0
1991-01-01 France FRA 58554242.0
1992-01-01 France FRA 58846584.0
1993-01-01 France FRA 59103094.0
1994-01-01 France FRA 59324863.0
1995-01-01 France FRA 59541294.0
1996-01-01 France FRA 59754504.0
1997-01-01 France FRA 59968066.0
1998-01-01 France FRA 60190684.0
1999-01-01 France FRA 60501986.0
2000-01-01 France FRA 60918661.0
2001-01-01 France FRA 61364377.0
2002-01-01 France FRA 61812142.0
2003-01-01 France FRA 62249855.0
2004-01-01 France FRA 62707588.0
2005-01-01 France FRA 63180854.0
2006-01-01 France FRA 63622342.0
2007-01-01 France FRA 64016890.0
2008-01-01 France FRA 64375116.0
2009-01-01 France FRA 64706436.0
2010-01-01 France FRA 65026211.0>
# on peut maintenant dessiner
df_france[['population']].plot();