fichiers et formats#
Licence CC BY-NC-ND, Thierry Parmentelat & Aurélien Noce
commencez par télécharger le zip
on va faire quoi ?#
les fichiers et l’OS; comment ouvrir, pourquoi fermer ?
différents formats de fichier usuels
texte simple sans accent, typiquement en anglais (ASCII)
texte standard (utf-8)
pickle (ouille ça pique, c’est du binaire)
json (on se sent un peu mieux)
csv (ah là on parle)
yaml (de plus en plus populaire)
comment parser un format de fichier custom
modalités du TP#
on ouvre vs-code
on participe
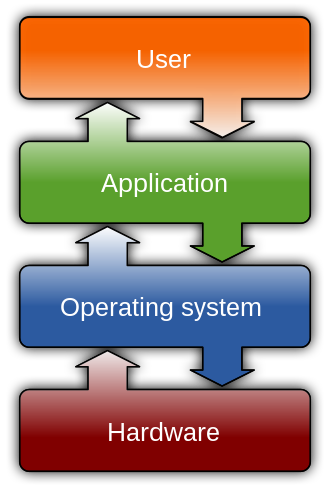
les fichiers et l’OS#
c’est quoi l’OS ?
votre code ne cause jamais directement au harware
mais toujours au travers d’abstractions exposées par l’OS
parmi lesquelles, entre autres, la notion de “fichier”
questions préliminaires#
qu’est-ce qu’un fichier ?
que contient un fichier ?
quelles sont les étapes pour y accéder ?
lire un fichier simple#
(le fichier hello.txt fait partie du zip)
ouverture d’un fichier#
f = open("hello.txt")
que se passe-t-il ?
pensez à consulter la documentation (comment on la trouve ?)
que peut-on faire de
f?que pensez-vous de cette version alternative ?
# ça marche aussi; quelle différence ? f = open("hello.txt", encoding="utf-8")
les types#
analyser les types des différents objets
type("hello.txt") type(f)
avancer étape par étape
il faut fermer !#
que se passe-t-il si on oublie de fermer le fichier ?
on va écrire un code qui ouvre
nfichiers le faire tourner avecn= 10, 100, 1000, …
pouvez-vous prédire ce qui va passer ?
l’idiome pour lire un fichier: with & for#
toujours utiliser with
l’idiome à toujours utiliser pour lire un fichier texte
# TOUJOURS lire ou écrire un fichier avec un with !
with open("hello.txt") as f:
for line in f:
print(line, end="")
quelles autres formules connaissiez-vous pour faire ça ?
pourquoi le end=”” ?
à chaque itération, vous allez trouver dans la variable line, eh bien la ligne suivante évidemment,
sauf que ceci contient un caractère de fin de ligne - qu’on appelle aussi newline
du coup si vous faites un print(line) (essayez..) vous allez avoir une ligne blanche sur deux !
une autre approche consisterait à utiliser line.rstrip() qui enlève l’éventuel newline;
je dis éventuel car la dernière ligne ne contient pas toujours ce fameux newline; le monde est compliqué parfois…
exercice: dans vs-code, allez enlever le dernier newline (mettez vous à la fin du fichier et faites un Delete)
et refaites tourner les 3 lignes ci-dessus; vous pouvez aussi regarder ce que donne cat hello.txt dans le terminal.
contenu des fichiers texte#
on va regarder dans les yeux deux fichiers texte:
ASCII#
installez l’extension vscode Hex Editor
regarder le contenu de
hello.txtavec vs-codeutilisez clic droit -> Open With -> Hex Editor
comparez avec https://www.rapidtables.com/code/text/ascii-table.html
Unicode#
faites pareil avec bonjour.txt
que constatez-vous ?
voyez aussi https://www.utf8-chartable.de/
un fichier binaire#
faites pareil avec tiny.pickle
ouvrez-le “normalement” (pour l’instant sans utiliser la librairie
pickle)comment faut-il adapter le code ? indice: il faut utiliser le mode d’ouverture et spécifier binaire
que constatez-vous ? (indice: les types !)
à retenir : texte ou binaire
un fichier peut contenir
du texte (qu’il faut alors décoder, généralement avec
encoding='UTF-8'), on obtient alors unstrdu binaire - on obtient alors des
bytes; dans ce cas on n’a pas besoin de fournir un encodage pour lire le fichier of course… - par contre c’est souvent l’application, ou une librairie, qui va se taper le décodage, plus ou moins à la main selon les cas.
les différents formats de fichier#
Tout le monde ne crée pas sa propre structure (on dit aussi format) de fichier !
Il existe des formats standard qui permettent une interaction entre les programmes, et même différents langages de programmation !
le format pickle#
c’est le format intégré de Python:
c’est un format binaire: s’ouvre avec
open(name, 'rb')permet de sérialiser notamment les types de base, c-a-d non seulement des atomes (nombres, chaines…)
mais aussi des structures plus complexes, avec des containers etc…
par contre, il ne va pas convenir pour échanger avec d’autres langages…
b pour binaire
dans open(name, 'rb') le r est pour read et le b pour binary
à faire:
lisez la documentation du module
pickleessayez de lire le fichier
tiny.pickleinspectez les types des objets dans la donnée
pickle : écriture#
partez de ce que vous venez de lire
modifiez certaines des données
sauvegardez-les dans un nouveau fichier
tiny-changed.pickleet relisez-le pour vérifier que “ça marche”
autre format: json#
à vous de jouer
on va refaire pareil à partir de
tiny.jsonlisez-la doc et écrivez le code qui lit ce fichier
modifiez la donnée lue, et sauvez-la
est-ce qu’on peut y mettre un ensemble ? ou un tuple ?
encore un: yaml#
trouvez la doc de
PyYAMLlisez le fichier
tiny.yamlcomment peut-on comparer avec JSON ?
et avec annotations ?
en option: par défaut le format YAML permet de stocker - comme JSON - les types communs aux autres langages,
i.e. booléens, nombres, chaines, listes et dictionnaires; il est possible aussi de stocker des types un peu moins communs comme le tuple et l’ensemble, au prix d’une gymnastique déjà un peu oins facile d’accès; arrivez-vous à lire le fichier small-annotated.yaml ?
ça peut demander une plangée dans SO (stackoverflow)…
et aussi: les csv#
on recommence (c’est optionnel, si vous savez déjà lire un csv avec pandas)…
lisez la documentation du module
csv
googlepython module csvessayez de lire le fichier
pokemon.csvsauriez-vous créer une dataframe ?
version facile: avec
pd.read_csv()un peu moins simple: sans utiliser
pd.read_csv()
formats custom#
comment peut-on lire (on dit parse) des formats de fichiers inconnus ?
pour cela, 2 armes
le type
strfournit plein de méthodes - notammentstrip(),split()etjoin()le module
re(pour regular expressions) peut également être utile
exercice: lisez notes.txt#
sans importer de module additionnel,
lisez le fichier
notes.txtcréez et affichez un dictionnaire
nom élève → note
un mot sur print()
c’est l’opération la plus simple pour sauver un résultat..
mais ce n’est pas très utile en réalité, car le plus souvent limitée à un lecteur humainil est souvent plus utile de sauver ses résultats dans un des formats qu’on vient de voir - typiquement json ou csv
mais pour info, on peut écrire dans un fichier
f(ouvert en écriture) avecprint(des, trucs, file=f)
les redirections de bash (pour info)
quand il est lancé, votre programme a un
stdinet unstdout(et unstderrmais c’est plus anecdotique)qui sont créés par bash (et sont branchés sur le terminal)
vous pouvez les rediriger en faisant
python myhack.py < the-input > the-output
exercice: écrivez un programme#
qui lit sans fin le texte entré dans le terminal
regarde si le texte commence par un
qsi oui c’est la fin du programme
sinon affiche le nombre de mots dans la ligne
et recommence
consigne
ne pas utiliser input(), mais plutôt sys.stdin
indices
de quel type est
sys.stdin?si vous voulez ajouter un prompt
(un peu comme les>>>de python)
lancez votre programme avecpython -u mycode.py
épilogue: les regexps, en deux mots#
sans transition..
l’idée est de décrire une famille de chaines
à partir d’une autre chaine (la regexp)
qui utilise des opérateurs
comme p.e.
*pour indiquer ‘un nombre quelconque de fois’ telle ou telle autre regexp
exemple de regexp
ab((cd)|(ef))* décrit un ensemble qui
ne contient que des mots qui commencent par
abcontient
abcdet aussiabefou encore
abcdcdefcdmais pas
abceniabcde
avertissement
Some people, when confronted with a problem, think “I know, I’ll use regular expressions.” Now they have two problems.